개인 블로그 어드민 운영하다 만난 Vercel Blob list() 비용 이슈와 CDC 캐시
파일은 Blob, 목록은 DB, 페이지는 ISR
TL;DR
- 문제: Vercel Blob list() 호출이 월 약 2,600회까지 증가해 무료 티어(2,000 ops/월) 초과
- 원인: 파일 목록/검색/페이지네이션/이미지 피커 UI가 사용자 액션마다 list()를 재호출
- 해결: Blob 메타데이터를 Postgres에 CDC(변경사항 동기화) 캐시로 유지해 list() 호출 상한을 고정
- 결과: list() 호출 약 91% 절감 (2,600 → 240 ops/월), 목록 응답 P95 기준 약 10배 개선 (1,200ms → 120ms)
- 핵심 원칙: 목록은 DB(Postgres), 본문은 Blob, 렌더링은 ISR
퇴사 후, 블로그 편집 경험을 먼저 고쳤다
블로그 글을 꾸준히 쓰기 위해 가장 큰 병목은 “글의 품질”보다 “쓰기까지 걸리는 마찰”이었다.
기존에는 파일시스템 기반으로 글을 관리했고, 글을 조금만 고치려 해도 IDE와 배포 과정이 필요했다.
반복되는 루틴
- IDE 열기
content/posts/...에 MDX 파일 생성- Front matter 작성
- 본문 작성
git add/commit/push- 배포 대기
- 수정 필요 시 다시 1번부터
이 과정은 “어디서든 빠르게 쓰고, 자주 고치고, 바로 확인하기”와 반대 방향이었다.
그래서 글 저장소를 파일시스템에서 Vercel Blob으로 옮기고, 블로그는 읽기 전용으로 유지하는 구조로 바꿨다.
파일시스템에서 Vercel Blob으로
기존 구조는 단순했다.
content/posts/
├── DEV/nextjs-ssr.mdx
└── REACT/hooks.mdx
빌드 시: fs.readFileSync() → 페이지 생성
파일시스템의 제약
- 글을 고치려면 IDE/로컬 환경이 필요
- 오타 수정 같은 작은 변경도 커밋/배포 단계를 거침
- “일단 써두고 다듬기”가 쉽지 않음
변경: Blob을 원본(SSoT)으로
- 어디서든 업로드/수정(브라우저 기반)
- Blog는 읽기만
- 코드 변경이 없으면 배포 없이 운영
Blog-Admin을 만들었고, 거기서 list() 비용이 터졌다
Blob으로 옮기면 곧바로 필요해지는 것이 관리 UI다. 나는 Blog-Admin(Next.js)을 만들고 다음 기능을 붙였다.
- 파일 목록(검색/필터/페이지네이션)
- 마크다운 편집 + 프리뷰(실제 렌더 파이프라인 재사용)
- 이미지 업로드(Drag & Drop + URL 삽입)
export default async function FilesPage() {
const { blobs } = await list({ prefix: "posts/" }); // 문제의 시작
return <FileTable files={blobs} />;
}
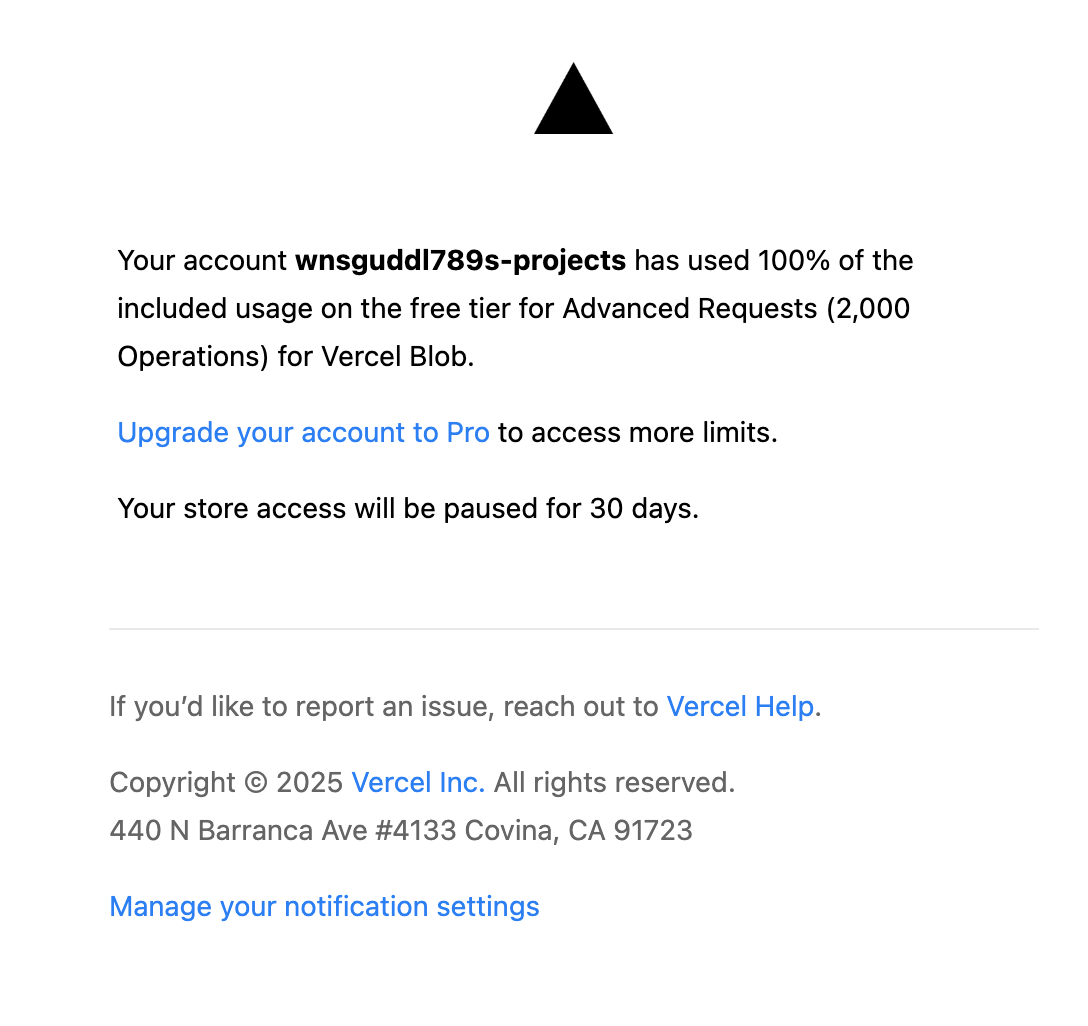
그리고 겨우 하루 지나, Vercel에서 “Blob Free Tier usage exceeded” 메일을 받았다.
- 업로드는 한 달에 20번도 안 했는데
- operations가 2,000을 넘어 있었다
이때부터 “쓰기”가 아니라 “조회”가 비용을 만든다는 사실을 확인하기 시작했다.
원인: list()는 ‘조회’가 아니라 ‘조작(ops)’이었다
Blob 비용 모델에서 put/delete/list는 모두 operations에 포함된다.
문제는 업로드/삭제가 아니라 list() 호출량이었다.
list() 호출이 폭증한 실제 패턴
- 페이지 로드/새로고침: 목록 화면을 자주 열수록 호출이 누적된다.
- 검색(키 입력 단위): 입력/수정/오타 교정 과정에서 여러 번 호출된다.
- 이미지 피커: 글 작성 중 이미지를 넣고 교체하면서 반복 호출된다.
- 페이지네이션: 파일이 쌓일수록 페이지 이동 자체가 추가 호출을 만든다.
월 ops로 환산
하루 평균:
- 파일 목록: 10회
- 검색: 15회
- 이미지 피커: 10회
- 페이지네이션: 5회
- 개발/테스트: 20회
───────────────
총: 60회/일
30일: 60 × 30 = 1,800회
개발 주말 4일: 200회/일 × 4 = 800회
────────────────────────
총합: 약 2,600회/월
업로드는 드물지만 list()는 매일 누적된다. 파일이 늘수록 더 악화되는 형태였다.
해결: Postgres CDC 캐시로 list() 호출 상한을 고정한다
이미 Auth/RBAC 때문에 Postgres(Neon) + Prisma가 있었다. 그래서 방향은 명확했다.
Blob은 원본(파일 실체)으로 유지하고, Blob 메타데이터 목록만 Postgres에 복제해 조회는 DB에서 처리한다.
설계원칙
- Blog는
list()를 절대 호출하지 않는다- 목록은 RPC로 캐시된 결과만 받는다.
list()는 주기 동기화에서만 호출한다(상한 고정)- 예: 30분 간격으로 최대 1회.
- 본문은 Blob 그대로 사용한다
- 목록/검색은 DB, 본문 다운로드는 Blob URL.
- 업로드/삭제는 훅으로 즉시 반영한다
- 주기 동기화만으로 생기는 “업로드 직후 목록 미반영” 문제를 해결.
아키텍처
---
config:
theme: redux
look: handDrawn
---
flowchart TB
subgraph Admin["Blog-Admin"]
A1["put/del → Blob"]
A2["Upload/Delete Hook<br/>DB 즉시 반영"]
A3["Periodic Sync<br/>(30분마다 list 1회)"]
A4["RPC API"]
end
subgraph BlobStore["Vercel Blob Storage"]
B1["posts/**"]
B2["images/**"]
end
subgraph DB["Postgres"]
D1["BlobFile 캐시 테이블"]
D2["SyncState<br/>(lastSyncAt)"]
end
subgraph Blog["Blog (Next.js)"]
C1["RPC로 목록 조회"]
C2["Blob URL로 본문 fetch"]
C3["ISR revalidate<br/>(60s)"]
end
%% (1) Admin put/del -> Blob
A1 -->|1| B1
A1 -->|1| B2
%% (2) Upload/Delete Hook -> DB 즉시 반영
A2 -->|2| D1
%% (3) Periodic Sync: Blob list (30분)
A3 -->|3| B1
A3 -->|3| B2
%% (4) Periodic Sync 결과 DB 반영 + lastSyncAt 갱신
A3 -->|4| D1
A3 -->|4| D2
%% (5) Blog 목록 조회: RPC -> (내부적으로 DB 조회)
C1 -->|5| A4
A4 --> D1
%% (6) Blog 본문 fetch: Blob URL
C2 -->|6| B1
%% ISR은 대개 내부 동작(페이지 갱신 트리거)이라 연결선은 선택사항
%% C3 -.-> C1
구현 요약
캐시 테이블(BlobFile)
model BlobFile {
id String @id @default(cuid())
url String @unique
pathname String
size BigInt
uploadedAt DateTime
contentType String?
syncedAt DateTime @default(now())
isDeleted Boolean @default(false)
@@index([pathname])
@@index([isDeleted])
}
메타데이터 캐시를 위한 테이블을 만들고, 삭제는 Soft delete로 처리했다.
Soft delete를 선택한 이유
- 실수로 삭제한 파일 추적이 가능
- 재업로드 시 복구 처리 가능
- 동기화 로직이 단순해진다(“없어졌으면 delete 표시”)
“마지막 동기화 시각”을 분리
파일 row의 updatedAt/lastChecked에 의존하면, 업로드 훅이 특정 row를 갱신했을 때 전체 sync 판단이 흔들릴 수 있다.
그래서 마지막 sync 시각은 별도 상태로 분리했다.
model SyncState {
id String @id
lastSyncAt DateTime
}
주기 동기화(Sync): Blob 전체 목록 1회 + Diff
동기화 시점에만 list()를 1회 호출하고, DB에 있는 캐시와 diff를 계산해 신규/삭제를 반영한다. “마지막 동기화 시각”은 파일 row 업데이트에 의해 흔들리지 않도록 SyncState 같은 별도 상태로 관리하는 편이 안전하다.
async function syncBlobToDatabase() {
// 1) Blob 전체 목록: 이 위치에서만 list() 1회
const { blobs } = await list();
// 2) DB 캐시
const dbFiles = await prisma.blobFile.findMany({
where: { isDeleted: false },
select: { url: true },
});
// 3) Diff
const blobUrls = new Set(blobs.map((b) => b.url));
const dbUrls = new Set(dbFiles.map((f) => f.url));
const newFiles = blobs.filter((b) => !dbUrls.has(b.url));
const deletedUrls = [...dbUrls].filter((url) => !blobUrls.has(url));
// 4) 반영
await prisma.$transaction([
prisma.blobFile.createMany({
data: newFiles.map((b) => ({
url: b.url,
pathname: b.pathname,
size: b.size,
uploadedAt: b.uploadedAt,
contentType: b.contentType,
})),
skipDuplicates: true,
}),
prisma.blobFile.updateMany({
where: { url: { in: deletedUrls } },
data: { isDeleted: true, syncedAt: new Date() },
}),
prisma.syncState.upsert({
where: { id: "blob" },
create: { id: "blob", lastSyncAt: new Date() },
update: { lastSyncAt: new Date() },
}),
]);
return { added: newFiles.length, deleted: deletedUrls.length };
}
업로드 훅: 즉시 반영(UX 보완)
주기 동기화만 있으면 업로드 직후 목록에 바로 안 보일 수 있다. 업로드/삭제 성공 시 DB를 즉시 업데이트해 UX를 보완했다. 업로드 자체는 Blob이 원본이므로, 훅 실패는 non-blocking으로 처리해도 된다. 훅이 실패해도 파일은 Blob에 존재하고, 다음 주기 동기화에서 자동으로 맞춰진다.
목록 조회는 RPC로, 내부는 DB로
Blog가 DB에 직접 붙지 않게 했다.
- DB 크리덴셜을 Blog 쪽으로 들고 가지 않기 위해
- 책임 분리를 위해(Admin가 메타데이터 API 제공)
// Admin RPC
app.get("/api/rpc/getBlobFiles", async (c) => {
if (await needsSync()) {
await syncBlobToDatabase();
}
const files = await prisma.blobFile.findMany({
where: { isDeleted: false },
orderBy: { uploadedAt: "desc" },
});
return c.json({ files });
});
// Blog client
export async function getBlobFiles() {
const response = await client.api.rpc.getBlobFiles.$get({})
const { files } = await response.json();
return files;
}
RPC 라우트는 다음 흐름을 가진다.
- lastSyncAt 확인
- 필요하면 sync 수행
- DB 조회 결과 반환
본문은 Blob에서, 렌더는 ISR로
목록은 DB 캐시로 가져오고, 본문은 해당 Blob URL에서 가져온다. 본문까지 DB에 넣지 않은 이유는 다음과 같다.
- Next.js ISR이 이미 “렌더 결과 캐시” 역할을 한다
- 본문은 Blob CDN에서 빠르게 내려받을 수 있다
- DB 용량/부하를 불필요하게 늘리지 않는다
결과
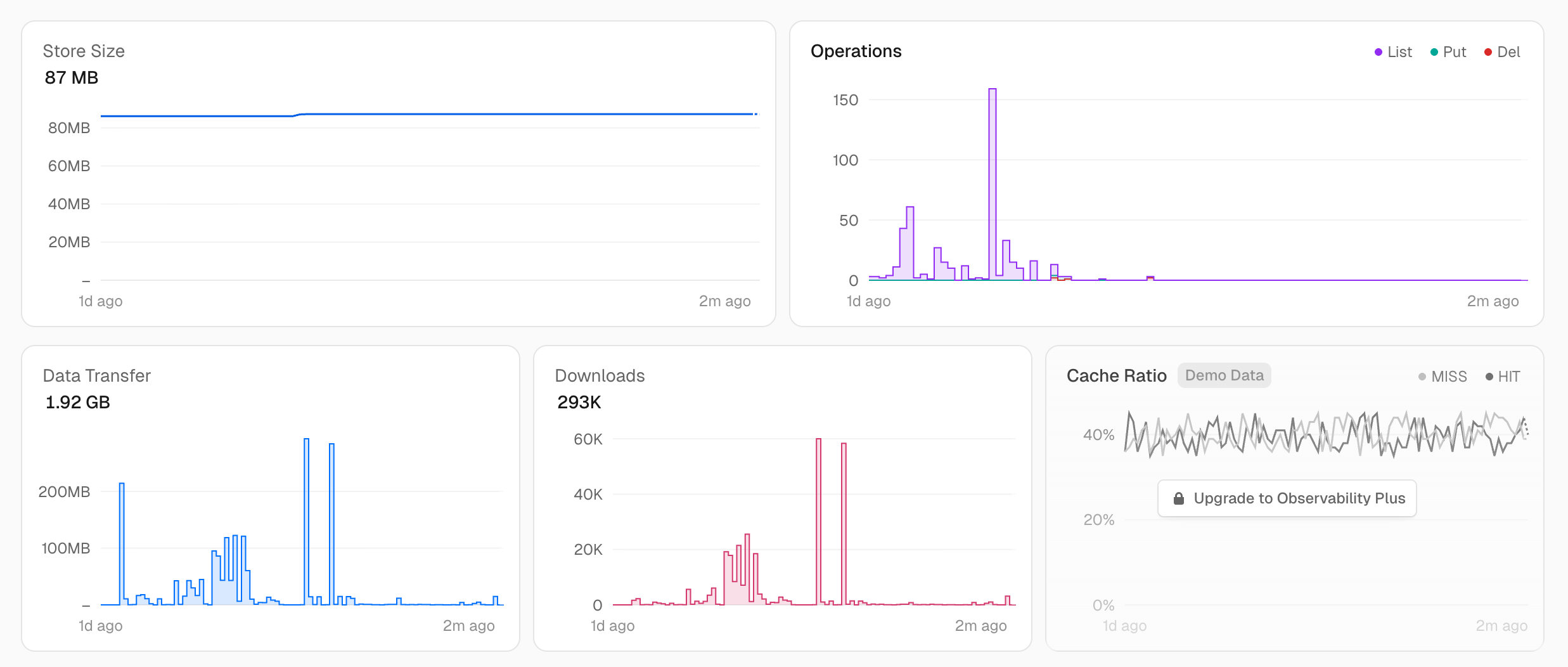
list() 호출량 감소: 약 91%
- AS-IS : 월 약 2,600 ops(
list()중심 ) → 무료 티어 초과 - TO-BE : 동기화 상한을 30분으로 고정하고, 훅은
list()없이 DB만 업데이트 → 월 약 240 ops 수준
응답 속도 개선: P95 기준 약 10배
목록 API의 서버 응답 시간을 로그로 수집해 분위수(P50/P95/P99)를 계산했다.
- AS-IS(Blob
list()기반) : P50 480ms / P95 1,200ms / P99 2,100ms - TO-BE(Postgres query 기반) : P50 52ms / P95 120ms / P99 180ms
P95 기준 약 10배 개선이다.
받아들인 트레이드오프
Eventually Consistent
훅이 실패하면 업로드 직후 잠시 목록이 stale일 수 있다.
- 파일은 Blob에 존재(원본)
- 다음 주기 동기화에서 자동 보정
- 개인 블로그 운영에서는 충분히 허용 가능한 수준
list()를 완전히 0으로 만들지 않았다
Webhook 기반 완전 실시간 동기화가 가능하면 0에 가까워질 수 있지만, 이 글의 목표는 “완벽”이 아니라 “상한 고정”이었다.
- 상한이 고정되면 비용은 예측 가능해진다
- 무료 티어 2,000 ops 대비 충분히 여유가 생긴다
DB 의존성
DB 장애 시 Admin 기능이 영향을 받을 수 있다. 다만 이미 Auth/RBAC로 DB는 필수였고, 필요하면 “긴급 모드”로 Blob list()를 직접 호출하는 fallback도 가능하다.
마무리
이 문제를 해결하면서 가장 중요했던 것은 “비용이 비싸다”는 감각이 아니라, 정확히 무엇이 ops를 발생시키는지(= list() 호출 패턴)를 먼저 확인하는 것이었다.
파일을 Blob으로 옮긴 뒤에야 비로소 드러난 비용 문제였지만, 메타데이터를 DB로 캐시하는 구조로 바꾸니 비용도 성능도 동시에 정리됐다.
결론은 한 줄이다.
파일은 Blob(원본), 목록은 Postgres(캐시), 렌더는 ISR(결과 캐시).