블로그 오버엔지니어링해보기 (w/RAG 시스템 구축 및 문서 자동화)
퇴사 후, 블로그를 오버엔지니어링하기 시작한 이유
회사에서 일하면서 계속 느꼈던 게 있다. 문서가 없다.
기획 문서가 안 남거나, 정책이 바뀌었는데 문서가 안 업데이트되거나, 새로운 사람이 들어와서 "이거 왜 이래요?"라고 물으면 아무도 모르거나. 그래서 항상 생각했다. "코드에서 문서를 자동으로 뽑아낼 수 없을까?"
그러다 지인인 박창준님이 쓴 RAG 기반 온보딩 챗봇 구축하기 글을 봤다. 창준님도 똑같은 문제를 겪었고, AI 에이전트를 활용해서 코드에서 기획 문서를 역추출하는 시스템을 만들었더라.
읽으면서 생각했다. 이거 나도 할 수 있겠는데?
좋은 아이디어를 보고 "와, 좋네" 하고 넘어가면 끝이다. 나중에 팀에서 "우리도 문서 자동화 도입하면 좋겠는데요"라고 제안할 때, "어디서 봤는데요"라고 말하는 것과 제가 직접 만들어봤는데요라고 말하는 건 설득력이 다르다.
마침 퇴사하고 시간이 생겼다. 그래서 결심했다.
내 블로그를 오버엔지니어링해서, 창준님이 만든 걸 내 손으로 재현해보자.
단순히 글을 올리는 공간이 아니라, 실제 조직에서 사용 가능한 수준의 인프라를 개인 프로젝트로 구축해보자는 목표였다.
오버엔지니어링에 대한 내 생각
보통 "오버엔지니어링"은 부정적인 의미로 쓰인다. 필요 이상의 복잡도를 더하는 일이니까. 하지만 내게는 다른 의미였다.
첫째, 실전 경험 상황 연출. 개인 프로젝트지만 실무 수준의 고민을 해보고 싶었다.
둘째, 패턴 축적. 다른 조직에 가서도 바로 적용 가능한 아키텍처 패턴을 만들고 싶었다.
셋째, 문서화된 지식. "이런 문제를 이렇게 해결했더라"는 기록을 남기고 싶었다.
즉, 지금은 내 블로그지만, 나중에 어떤 조직에 가도 작동할 시스템을 만들고 싶었다.
문제: 코드에는 다 있는데, 아무도 모른다
블로그에 Blog-Admin을 만들면서 1인 개발을 하고 있었다. 혼자서 기획, 디자인, 개발, 배포를 다 한다. 모든 의사결정이 내 머릿속에서 일어난다.
그러다 문득 생각이 들었다. 회사에서 이렇게 일하면 미래의 부채 아닌가?
실제로 신규 제품 조직에서 일할 때 이런 상황을 많이 겪었다. 빠르게 진행하다 보니 즉석에서 기획하고, 즉석에서 정책을 만들고, 즉석에서 결정했다. 기록이 안 남았다.
새로운 사람이 들어오면?
- "이 기능 왜 이렇게 되어있어?"
- "이 정책 언제 결정된 거야?"
답은 모르겠습니다가 된다. 문서가 없으니까.
그런데, 코드에는 다 있다
1인 개발할 때 기획 문서를 안 쓴 이유는 간단하다. 코드가 곧 정책이고, 코드가 곧 기획이니까.
BlobFile모델을 보면 "pathname이 unique identifier야"라는 정책이 보인다- API route를 보면 "이 기능이 왜 필요한지"가 보인다
내 머릿속에 있는 생각이 코드에 그대로 녹아 있다.
문제는 회사에서는 이게 안 된다는 거다. 수백 개 파일에서 필요한 로직을 찾고, 왜 그렇게 짰는지 추론하는 건 시간이 너무 오래 걸린다. 비즈니스 맥락, 당시의 제약조건 같은 건 코드에 없다.
코드에서 기획을 뽑아내자
그래서 결론에 도달했다.
코드를 읽어서 기획 문서를 뽑아내자.
보통은 [기획 → 디자인 → 개발] 순서로 진행된다. 하지만 회사에서는 기획 문서가 누락되는 경우가 많다.
그렇다면 반대로 하면 된다. **[코드 → 기획 문서]**로 복원하면 된다.
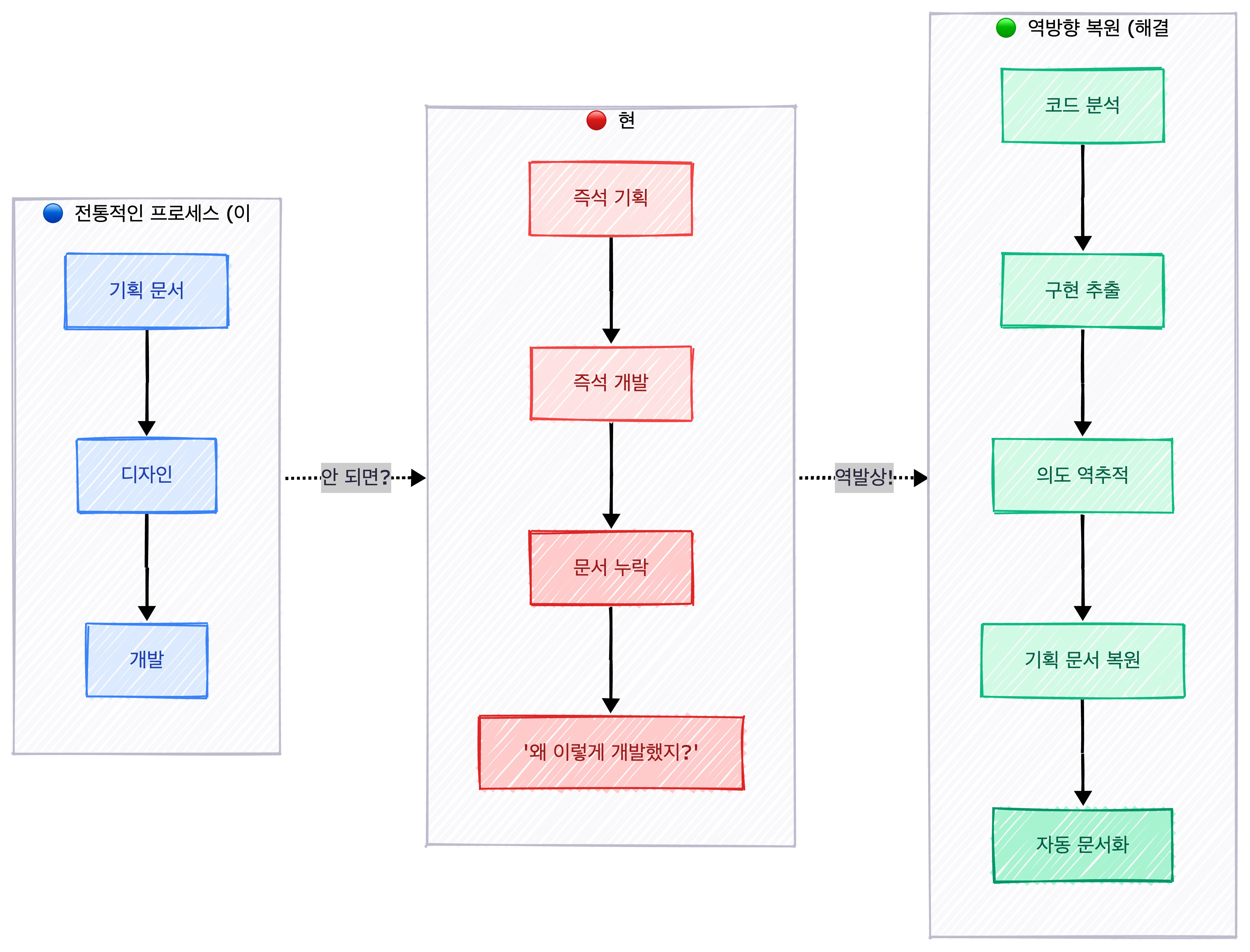
이게 내가 RAG 시스템과 문서 자동화를 만든 진짜 이유다.
RAG 시스템 아키텍처
구축한 RAG 시스템은 크게 Ingestion 파이프라인과 Query 파이프라인으로 나뉜다.
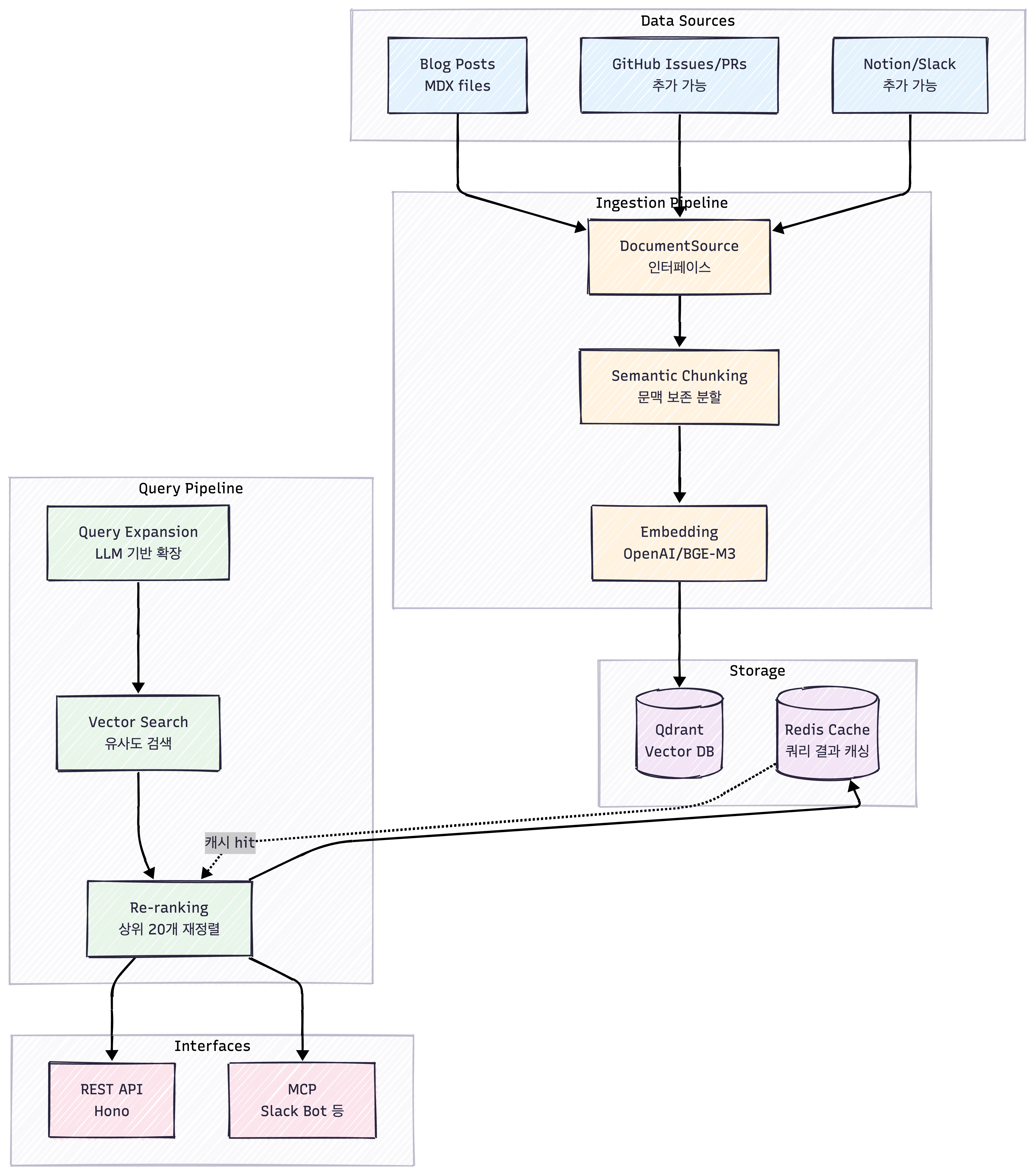
핵심 설계 포인트:
- 확장 가능한 데이터 소스:
DocumentSource인터페이스로 블로그 글, GitHub Issues, Notion 등 다양한 소스 지원 - 문맥 보존 Chunking: 단순 글자 수 자르기가 아니라, 문단 구조와 헤더를 보존
- 다중 Embedding 지원: OpenAI(상용) + BGE-M3(오픈소스)로 비용과 품질 트레이드오프
- 캐싱 계층: Redis로 자주 검색하는 쿼리 결과 캐싱
- 다중 인터페이스: REST API뿐만 아니라 MCP로 Slack Bot 등 다양한 클라이언트 지원
다른 조직에서도 작동하게
RAG 시스템을 설계할 때 다른 조직에 가져가도 작동하게를 목표로 삼았다.
인프라 독립성
어떤 조직은 OpenAI를 쓸 수 없고, 어떤 곳은 보안 문제로 클라우드를 못 쓴다. 그래서 Embedding 프로바이더, LLM 프로바이더, Vector DB를 모두 교체 가능한 인터페이스로 설계했다. 환경 변수만 바꾸면 OpenAI에서 GLM-4로, Qdrant Cloud에서 On-premise로 바꿀 수 있다.
데이터 소스 추상화
실제 조직에서는 블로그 말고도 GitHub Issues, Notion 페이지, Confluence, Slack 대화 기록 등 다양한 곳에 지식이 흩어져 있다. DocumentSource라는 인터페이스를 만들어서 어떤 문서든 똑같은 파이프라인으로 ingest 가능하게 했다.
API 우선 설계
어떤 조직이든 UI는 다르다. 어떤 곳은 Slack bot을 원하고, 어떤 곳은 Web dashboard를 원한다. Hono로 타입 안전한 API를 먼저 만들고, UI는 나중에 붙였다.
기술 스택 선택
| 컴포넌트 | 선택 기술 | 이유 |
|---|---|---|
| API 서버 | Hono | Express보다 가볍고, 어떤 호스팅에서도 작동 |
| Vector DB | Qdrant Cloud | On-premise도 가능해서 선택지 보유 |
| Embedding | OpenAI + BGE-M3 | 상용과 오픈소스 모두 지원 |
| LLM | GPT-4o-mini + GLM-4 | 비용 vs 성능 trade-off 커버 |
| 검증 | Zod | 타입 안전성 = 유지보수성 |
구현 패턴
1. Semantic Chunking
단순히 글자 수로 자르면 맥락이 파괴된다.
"React의 useState를 사용하면..."이라는 문장을 500자 단위로 자르면 "useState를 사용하면"과 다음 문장이 분리될 수 있다. 검색해도 안 나온다.
그래서 문단 구조, 헤더, 코드 블록을 보존하는 semantic chunking을 구현했다. 헤더를 만나면 새로운 청크를 시작하고, 코드 블록은 절대 분리하지 않는다.
2. Query Expansion
사용자가 "ISR"이라고 검색하면, 실제로는 "Incremental Static Regeneration", "정적 재생성", "Next.js caching"도 찾고 싶을 수 있다.
LLM을 사용해서 검색어를 자동으로 확장했다. 언어가 섞인 조직(한국어 + 영어)에서 특히 유용하다.
3. Re-ranking 전략
Vector similarity만으로는 부족할 때가 있다. 하지만 모든 결과를 re-ranking하면 느리고 비용이 많이 든다.
그래서 상위 20개만 re-ranking하는 전략을 썼다. 실전에서 제일 좋은 밸런스였다.

4. MCP (Model Context Protocol) 통합
RAG 시스템을 단순한 검색 엔진이 아니라, 도구로 만들었다. MCP로 만들어두면 Slack bot에서 도구로 호출 가능하고, 다른 LLM app에서도 재사용 가능하다.
문서 자동화 파이프라인: 창준님 접근법을 내 것으로
이제 본격적으로 앞에서 언급한 창준님의 접근법을 재현할 차례다.
창준님 글에서 핵심은 이거였다. 단일 에이전트로 "스펙 문서 작성해줘"라고 하면, "데이터가 어떻게 변한다"는 말해줘도 왜 변해야 하는가는 설명하지 못한다. 그래서 역할별로 에이전트를 쪼갰다.
- 코드 분석가: 코드베이스에서 페이지 구조, 스키마, API 엔드포인트를 추출 (Fact 위주)
- 도메인 분석가: 추출된 팩트에 비즈니스 맥락을 입힘 (Context 부여)
- 기획자: 이를 종합하여 사람이 읽기 좋은 '기능 명세서' 작성
나도 이 구조를 그대로 가져와서 내 블로그에 적용했다.

에이전트 구성

Stage 1: Explore Agent - 코드베이스 구조 파악
Monorepo 구조 분석, 핵심 디렉토리 식별, 의존성 관계 파악. apps/blog/는 Next.js 기반 블로그이고, apps/blog-admin/은 관리자 대시보드이고, apps/rag-gateway/는 RAG API 서버라는 걸 파악한다.
Stage 2: Facts Extractor - 기술적 사실 추출
코드에서 객관적인 사실만 추출한다. API 엔드포인트, 데이터 모델, 환경 변수 등. 의견이나 해석은 배제.
Stage 3: Insights Analyzer - 비즈니스 컨텍스트 분석
"왜"라는 질문에 답한다. Facts에는 "Qdrant를 사용한다"는 사실만 있지만, Insights에는 "Pinecone 대신 Qdrant를 선택한 건 On-premise 배포가 가능해서다"라는 맥락이 추가된다.
Stage 4: Specs Writer - 기능 명세서 작성
사용자가 이해할 수 있는 문서 작성. 개발자가 아닌 사람도 읽을 수 있게.
실제 결과물 예시
Facts 문서 (일부)
## API Endpoints
- `GET /api/rag/search` - 의미 기반 문서 검색
- Query params: `q` (검색어), `limit` (결과 수)
- Response: `{ results: Document[], total: number }`
- `POST /api/rag/ingest` - 새 문서 인덱싱
- Body: `{ source: string, documents: RawDocument[] }`
## Data Models
- `BlobFile`: pathname (unique), contentHash, updatedAt
- `VectorDocument`: id, embedding, metadata, chunkIndex
Insights 문서 (일부)
## 의사결정: Vector DB 선택
**선택**: Qdrant (Pinecone 대신)
**이유**:
- On-premise 배포 가능 (보안 요구사항 대응)
- 무료 티어로 프로토타이핑 가능
- Python/TypeScript SDK 모두 지원
**Trade-off**: Pinecone보다 생태계가 작음,
하지만 조직 요구사항 유연성이 더 중요하다고 판단
Specs 문서 (일부)
## RAG 검색 기능
### 개요
블로그 글을 의미 기반으로 검색할 수 있습니다.
단순 키워드 매칭이 아니라, 문맥을 이해해서 관련 글을 찾아줍니다.
### 사용 시나리오
1. 사용자가 "React 상태 관리"를 검색
2. 시스템이 "useState", "Redux", "Zustand" 관련 글도 함께 추천
3. 검색어를 정확히 몰라도 원하는 글을 찾을 수 있음
격리된 실패 패턴
LLM이 코드를 잘못 이해할 수도 있다. 그래서 한 단계가 실패해도 전체 파이프라인이 멈추지 않게 설계했다.
- Explore Agent 실패 → 기본 파일 목록으로 fallback
- Facts Extractor 실패 → 빈 Facts 문서 생성, 다음 단계로 넘어감
- Insights Analyzer 실패 → Facts만으로 Specs 생성
없는 것보다 낫다는 철학이다.
GitHub Actions 통합
name: Documentation Auto-Update
on:
push:
branches: [main]
workflow_dispatch:
inputs:
force_full_update:
description: 'Force full documentation update'
required: false
type: boolean
default: false
main 브랜치에 푸시되면 자동으로 실행된다. 코드가 변경되면 문서도 자동으로 업데이트된다.
읽는 것과 만드는 것의 차이
이 시스템을 직접 만들면서 깨달은 게 있다.
창준님 글을 읽었을 때는 "아, 에이전트를 분리하면 되는구나" 정도로 이해했다. 하지만 직접 만들어보니 글에는 안 나온 문제들이 튀어나왔다.
- Explore Agent가 monorepo 구조를 제대로 파악 못 하면 어떻게 하지?
- Facts Extractor가 너무 많은 정보를 뽑으면 토큰 제한에 걸리는데?
- Insights Analyzer가 "왜"를 추론 못 하고 그냥 Facts를 반복하면?
이런 문제들을 하나씩 해결하면서 아, 이래서 이렇게 했구나가 몸에 새겨졌다.
읽으면 "아, 그렇구나" 하고 끝나지만, 만들면 내 것이 된다.
배운 것
1. 완벽한 문서가 없어도 괜찮다
문서를 작성하는 것보다, 자동으로 지식을 수집하는 시스템을 만드는 게 낫다. 코드 commit 메시지, PR 설명, 블로그 글이 다 소재가 된다.
2. 오버엔지니어링은 설득의 자산이 된다
단순히 "과도한 설계"가 아니라, 다음을 위한 투자다.
다음 조직에 가서 "이런 시스템 도입하면 어떨까요?"라고 제안할 때, 블로그 링크 하나 던지면 된다. "이론적으로는요..."가 아니라 제가 만들어봤는데요, 이런 문제가 있었고, 이렇게 해결했습니다라고 말할 수 있다.
3. 남의 경험을 내 것으로 만드는 법
좋은 글을 읽고 "와, 좋네" 하고 넘어가면 남의 경험으로 끝난다. 직접 만들어봐야 내 경험이 된다. 그래야 제안할 때 설득력이 생긴다.
마무리
퇴사 후 블로그를 오버엔지니어링한 것은, 창준님의 경험을 내 것으로 만들기 위한 투자였다.
빠르게 실패하되, 그 실패에서 배운 것은 잃지 말자. 그리고 그 배운 것을 다음 조직에서 설득의 근거로 쓰자.
참고 자료: